

فایل Robots.txt چیست و چه کاربردی دارد؟

اجازه دهید برای درک آسانتر فایل Robots.txt از یک مثال ساده شروع کنیم.
فرض کنید اولین بار برای انجام یک کار اداری وارد سازمان بزرگی میشوید؛ هیچ جایی را هم نمیشناسید. مدیران این سازمان هم چون میدانند مراجعه کنندهها همهجا را نمیشناسند، پس کنار در ورودی یک باجه اطلاعات درست کردهاند و یک یا چند نفر را مسئول راهنمایی و نگهبانی گذاشتهاند. اگر این افراد راهنما و نگهبان نباشند، کل سازمان دچار هرج و مرج میشود. هرکسی برای انجام کارهایش راهروها را بالا و پایین میکند و کارمندان هم نمیتوانند کارها را به درستی انجام دهند.
فایل Robots.txt در وبسایتها نقش همین راهنماها و نگهبانان را دارد اما نه برای کاربرانی که وارد سایت میشوند، بلکه برای رباتهایی که برای بررسی سایت یا هر کار دیگری میخواهند در بخشهای مختلف سایت سرک بکشند.
ربات؟!
خب بله دیگه. فقط آدمها بازدید کننده سایت شما نیستند که. رباتهایی هستند که به دلایل مختلفی به سایت شما سر میزنند.
رباتها در واقع نرمافزارهایی هستند که به صورت خودکار صفحههای مختلف را باز و بررسی میکنند.
رباتهای موتور جستجوی گوگل مهمترین رباتهایی هستند که در اینترنت میچرخند. این رباتها هر روز چندین بار صفحههای سایت شما را بررسی میکنند. اگر وبسایت بزرگی داشته باشید، امکان دارد رباتهای گوگل تا چند ده هزار بار در روز صفحههای سایت را بررسی کنند.
هر کدام از این رباتها کار خاصی میکنند. مثلاً مهمترین ربات گوگل یا همان Googlebot کارش پیدا کردن صفحههای جدید در اینترنت و دریافت آن برای بررسیهای بیشتر توسط الگوریتمهای رتبهبندی کننده است. پس رباتها نه تنها ضرری برای سایت شما ندارند، بلکه باید خیلی هم از آنها استقبال کرد.
اما باید حواستان باشد که این رباتها زبان آدمیزاد سرشان نمیشود! یعنی همینطور مثل چی سرشان را میندازند پایین و سر تا پای سایت را بررسی میکنند. بعضی وقتها هم رباتها گوگل چیزهایی را که دوست نداریم هر کسی ببیند را برمیدارند میبرند در سرورهای گوگل ذخیره میکنند و به عالم و آدم نشان میدهند. خب پس باید راهی باشد که جلوی آنها را بگیریم.
خوشبختانه دسترسی رباتها به صفحهها یا فایلها را میتوانیم کنترل کنیم.
میتوانید با نوشتن دستورهایی ساده در یک فایل به نام Robots.txt جلوی ورود ربات را به بخشهایی از سایت بگیرید، به آنها بگویید اجازه ندارند وارد بخشی از سایت شوند یا دستوراتی خاص بدهید تا سرور میزبان سایت شما الکی مشغول رباتها نشود و همینطور وبسایت خود را از نظر سئوی سایت بهینهسازی کنید.
 در ادامه میخواهیم با جزئیات کامل درباره همین فایل مهم صحبت کنیم. قدم به قدم جلو میرویم تا ببینیم چطور میتوان از فایل Robots.txt استفاده کرد؛ چطور میتوانیم رباتها را محدود کنیم، چطور از ایندکس شدن صفحهها جلوگیری کنیم و در نهایت یک فایل Robots.txt عالی بسازیم.
در ادامه میخواهیم با جزئیات کامل درباره همین فایل مهم صحبت کنیم. قدم به قدم جلو میرویم تا ببینیم چطور میتوان از فایل Robots.txt استفاده کرد؛ چطور میتوانیم رباتها را محدود کنیم، چطور از ایندکس شدن صفحهها جلوگیری کنیم و در نهایت یک فایل Robots.txt عالی بسازیم.
اول ببینیم این فایل Robots.txt دقیقاً چیست و چه وظیفهای دارد.
فایل Robots.txt چیست؟
فایل Robots.txt مثل یک مجوز دهنده به رباتها است. وقتی رباتها میخواهند صفحههایی از سایت را بررسی کنند، اول فایل Robots.txt را میخوانند. در این فایل با چند دستور ساده مشخص میکنیم که ربات اجازه بررسی کدام صفحهها را دارد و کدام صفحهها را نباید بررسی کند.
مثل تصویر زیر که در آن اجازه دسترسی به پوشهای به نام photos و اجازه دسترسی به صفحهای به نام files.html را ندادیم.
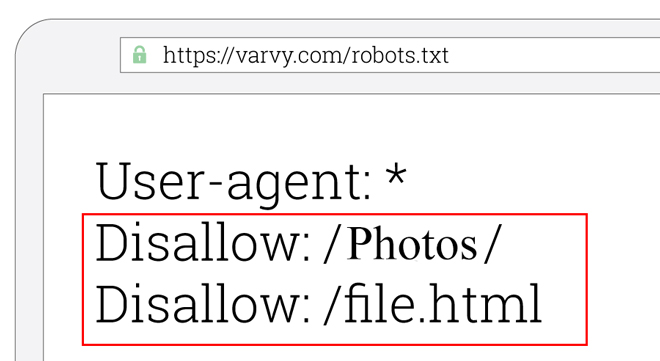 همانطور که گفتیم مهمترین رباتها در اینترنت رباتهای موتور جستجوی گوگل هستند پس ما در ادامه مقاله هرجا میگوییم ربات منظورمان رباتهای گوگل است.
همانطور که گفتیم مهمترین رباتها در اینترنت رباتهای موتور جستجوی گوگل هستند پس ما در ادامه مقاله هرجا میگوییم ربات منظورمان رباتهای گوگل است.
البته رباتهای دیگری متعلق به سرویس دهندههای مختلف اینترنتی هستند. بعد از خواندن این مقاله میتوانید هر نوع رباتی را فقط با دانستن نامش محدود و کنترل کنید.
چرا باید فایل Robots.txt داشته باشیم؟
صاحبان وبسایت و وبمسترها میتوانند ورود رباتها به وبسایت را از راههای مختلفی کنترل کنند. کنترل کردن هم دلایل مختلفی دارد.
مثلاً تمام صفحات یک سایت از درجه اهمیت یکسانی برخوردار نیستند. بیشتر وبمسترها علاقهای ندارند تا پنل مدیریت وبسایتشان در موتورهای جستجوگر ایندکس شود و در اختیار عموم قرار گیرد یا اینکه برخی از صفحات سایتشان محتوای قابل قبولی ندارد و به همین دلیل ترجیح میدهند آن صفحات توسط رباتها بررسی نشوند. یا اگر وبسایتی دارید که هزاران صفحه دارد و بازدید کل سایت هم زیاد است، احتمالاً دوست ندارید منابع سرور شما (پهنای باند، قدرت پردازشی و ..) برای بازدیدهای پشت سرهم رباتها مصرف شود.
اینجا است که فایل Robots.txt نقشآفرینی میکند.
در حال حاضر، هدف اصلی فایل ربات محدود کردن درخواستهای بیش از حد بازدید از صفحات وبسایت است. یعنی اگر رباتها میخواهند روزی شونصد بار یک صفحه را بررسی کنند، ما با نوشتن یک دستور ساده در فایل Robot جلوی آنها را میگیریم تا بفهمند رئیس کیست!
آیا با فایل Robots.txt میتوان صفحهای را از نتایج جستجو حذف کرد؟
تا همین چند وقت پیش اگر میخواستید صفحهای را به طور کامل از دید رباتهای گوگل دور کنید و حتی در نتایج جستجو دیده نشود.، با دستور noindex در همین فایل امکانپذیر بود اما حالا کمی داستان پیچیدهتر شده است.این فایل برای دور نگهداشتن صفحهها از موتور جستجوی گوگل کمک زیادی به حذف صفحه از نتایج جستجو نمیکند.
گوگل اعلام کرد که برای حذف صفحهها از نتایج جستجو، بهتر است از راههای دیگری به جز فایل Robots.txt استفاده کنید. البته در حال حاضر میتوان از این فایل برای خارج کردن فایلهایی مثل تصاویر، ویدیو یا صدا از نتایج جستجو استفاده کنید اما برای صفحات وب مناسب نیست.
راههای دیگر جایگزین برای حذف صفحه از نتایج جستجئی گوگل را در ادامه معرفی میکنیم.
آشنایی با رباتهای گوگل
گوگل تعدادی ربات خزنده (Crawler) دارد که به صورت خودکار وبسایتها را اسکن میکنند و صفحهها را با دنبال کردن لینکها از صفحهای به صفحه دیگر پیدا میکنند.
لیست زیر شامل مهمترین رباتهای گوگل است که بهتر است بشناسید:
- AdSense – رباتی برای بررسی صفحهها با هدف نمایش تبلیغات مرتبط
- Googlebot Image – رباتی که تصاویر را پیدا و بررسی میکند
- Googlebot News – رباتی برای ایندکس کردن سایتهای خبری
- Googlebot Video – ربات بررسی ویدیوها
- Googlebot – این ربات صفحات وب را کشف و ایندکس میکند. دو نوع Desktop و Smartphone دارد
هر کدام از این رباتها به صورت مداوم، صفحههای وبسایت را بررسی میکنند. شما میتوانید در صورت نیاز هرکدام از رباتها را محدود کنید.
این که رباتهای خزنده هر چند وقت یک بار به سایت شما سر میزنند به چند فاکتور بستگی دارد. هر چه در طول روز تعداد بیشتری محتوا در وبسایتتان قرار بگیرد و تغییرات سایت اهمیت زیادی داشته باشد، رباتهای جستجوگر دفعات بیشتری به سایت شما مراجعه میکنند. برای مثال، در وبسایتهای خبری که همیشه در حال انتشار خبر و بهروزرسانی اخبارشان هستند رباتها با سرعت بیشتری صفحات را بررسی و ایندکس میکنند.
در سرچ کنسول بخشی به نام Crawl Stats وجود دارد که دفعات بررسی صفحههای سایت به صورت روزانه را نمایش میدهد. در همین صفحه، حجم دانلود شده توسط رباتها و همینطور زمان بارگذاری صفحهها را میتوانید ببینید.
چرا فایل Robots.txt مهم است؟
این فایل به چند دلیل اهمیت دارد:
۱. مدیریت ترافیک رباتها به وبسایت
مدیریت ترافیک رباتها از این جهت اهمیت دارد که سرور میزبان وبسایت شما برای پردازش و بارگذاری صفحات برای رباتها مشغول نشود. از طرف دیگر، اکثر سرورها یا میزبانهای وبسایت از نظر پنهای باند و ترافیک محدودیت دارند؛ به همین دلیل مصرف ترافیک برای رباتها مقرون به صرفه نیست.
۲. جلوگیری از نمایش صفحات یا فایلها در نتایج جستجوی گوگل
اگر در فایل Robots دستور دهید که رباتهای گوگل اجازه دسترسی به صفحاتی را ندارند، این صفحات کلاً بررسی نمیشوند اما هیچ تضمینی وجود ندراد که این صفحه در نتایج جستجوی گوگل ظاهر نشود. امکان دارد رباتها از طریق لینکهایی که به همان صفحه داده شدهاند و کمک گرفتن از همان انکر تکست لینک، صفحه را ایندکس کنند. در حال حاضر بهترین راه برای حذف صفحهای از نتایج جستجو، اضافه کردن دستور noindex در قسمت head صفحهها است. اگر از وردپرس استفاده میکنید افزونههایی برای این کار وجود دارد و در غیر اینصورت باید از طراحی وبسایت خود بخواهید که امکاناتی برای افزودن این کدها یا دستورات در قسمت هد هر صفحه فراهم کند.
در بخشهای بعدی درباره حذف صفحه از نتایج جستجو کاملتر توضیح دادیم.
۳. مدیریت Crawl Budget
هرچه تعداد صفحات وبسایت شما بیشتر باشد، رباتهای موتور جستجو زمان بیشتری برای خزیدن و ایندکس کردن صفحات نیاز دارد. همین زمان طولانی، روی رتبه سایتتان در نتایج جستجو، تاثیر منفی خواهد گذاشت.
چرا؟ ربات خزنده موتور جستجوی گوگل (همان Googlebot خودمان!) دارای ویژگی به نام Crawl Budget است.
Crawl Budget در حقیقت تعداد صفحاتی از وب سایتتان است که ربات گوگل در یک روز آنها را خزیده و بررسی میکند. بودجه شما، یا همان تعداد صفحاتی که توسط Googlebot مشاهده می شوند، بر اساس حجم وبسایت شما (تعداد صفحات)، سلامت آن (عدم بروز خطا) و تعداد بکلینکهای سایتتان تعیین میشود.
Crawl Budget به دو بخش تقسیم میشود. اولین بخش، Crawl Rate Limit (حد نرخ خزیدن) است و دومی Crawl Demand. خب ببینیم معنی هر کدام چیست و چه تاثیری دارند.
Crawl Rate Limit
ربات گوگل (Googlebot)، به شکلی طراحی شده است تا شهروند خوبی برای دنیای اینترنت باشد. خزیدن، اولویت اصلی این ربات است پس طوری طراحی شده که تا بر تجربه کاربری بازدیدکنندگان سایت تاثیری نگذارد. این بهینهسازی Crawl Rate Limit نام دارد که برای ارائه تجربه کاربری بهتر، تعداد صفحات قابل Crawl در یک روز را محدود میکند.
به طور خلاصه، Crawl Rate Limit نشانگر دفعات ارتباط همزمان ربات گوگل با یک سایت در کنار دفعات توقف این ربات در عملیات خزش یا Crawling وبسایت است. نرخ خزش (Crawl Rate) میتواند بر اساس چند عامل تغییر کند:
- سلامت خزش (Crawl Health): اگر وبسایت سریع باشد و بتواند سیگنالها را به سرعت پاسخ دهد، مطمئناً Crawl Rate بالا میرود، اما اگر وبسایت شما کند باشد یا در حین Crawl خطاهای سروری به وجود بیاید، نرخ خزش ربات گوگل کاهش مییابد.
- تعیین محدودیت در Google Search Console: صاحبات وبسایتها میتوانند میزان خزش وبسایتشان را کاهش دهند.
خب، هنوز Crawl Budget را به یاد دارید؟ بخش دوم آن، Crawl Demand نام دارد. گوگل Crawl Demand را به این شکل توضیح میدهد:
Crawl Demand
حتی اگر ربات گوگل به حد Crawl Rate تعیین شده نرسد، در صورتی که تقاضایی برای ایندکس شدن وجود نداشته باشد، شما شاهد فعالیت کمی از سوی ربات گوگل خواهید بود. دو فاکتوری که نقش مهمی در تعیین Crawl Demand (تقاضای خزش) دارند، عبارتند از:
- محبوبیت: یعنی آدرسهایی که در اینترنت محبوبتر هستند، بیشتر از دیگر آدرسها خزیده میشوند تا در ایندکس گوگل تازهتر باشند.
- بیات شدن! (Staleness): گوگل طوری آدرسها را ذخیره میکند که از قدیمی شدن آنها جلوگیری کند.
به علاوه، اتفاقاتی که بر کل سایت تاثیر میگذارند مانند جابهجایی وبسایت، ممکن است میزان Crawl Demand را جهت ایندکس دوباره وبسایت بر روی آدرس جدید، افزایش دهند.
در نهایت، ما با بررسی Crawl Rate و Crawl Demand، مقدار Crawl Budget یک وبسایت را تعریف میکنیم. در واقع Crawl Budget، تعداد URLهایی است که ربات گوگل میخواهد و میتواند ایندکس کند.
خب، بیایید تعریف گوگل از Crawl Budget را یکبار دیگر بخوانیم:
Crawl Budget، تعداد URLهایی است که ربات گوگل میخواهد و میتواند ایندکس کند
مطمئناً شما هم میخواهید ربات گوگل Crawl Budget سایتتان را به بهترین شکل ممکن مصرف کند. به عبارت دیگر، ربات گوگل باید ارزشمندترین و مهمترین صفحات شما را بهتر و بیشتر بررسی کند.
البته گوگل میگوید که عوامل و فاکتورهایی وجود دارند که روی عملیات خزش و ایندکس شدن سایت، تاثیر منفی میگذارند:
- محتوای تکراری در سایت
- وجود صفحات خطا
- استفاده از Session Identifier
- وجود ناوبری ضعیف در سایت
- صفحات هک شده در وبسایت
- محتوای بیارزش و اسپم
هدر دادن منابع سرور برای این صفحات، باعث از بین رفتن Crawl Budget شما میشود. به این ترتیب صفحات ارزشمند و مهمی که واقعاً نیاز به ایندکس شدن دارند خیلی دیرتر به نتایج جستجو راه پیدا میکنند.
خب، بیایید به موضوع اصلی خودمان یعنی فایل robots.txt برگردیم.
اگر بتوانید فایل robots.txt خوبی ایجاد کنید، میتوانید به موتورهای جستجو (به خصوص Googlebot) بگویید که کدام صفحات را مشاهده نکند. در واقع با این کار به رباتها میگویید کدام صفحهها اصلاً در اولویت شما نیستند. حتماً شما هم نمیخواهید که ربات خزنده گوگل برای مشاهده و ایندکس محتوای تکراری و کم ارزش، سرورهای شما را اشغال کند.
با استفاده درست از فایل robots.txt می توانید به رباتهای جستجو بگویید که Crawl Budget سایتتان را به درستی مصرف کنند. همین قابلیت است که اهمیت فایل robots.txt را در سئو دوچندان میکند.
توجه کنید که اگر سایت شما فایل Robots.txt نداشته باشد هم رباتهای گوگل کار خودشان را میکنند. وقتی ربات میخواهد وبسایتی را بررسی کند. اگر چنین فایلی وجود نداشته باشد، ربات بدون هیچ محدودیتی به تمام بخشهای در دسترس سر میزند.
کم کم برویم ببینیم که چطور باید از فایل Robots استفاده کنیم. اما قبلش از محدودیتها بگوییم که بعد نگویید چرا از اول نگفتی!
محدودیتهای دستورات Robots.txt
فایل Robots محدودیتهایی دارد که باید بدانید.
۱. دستورات استفاده شده در فایل Robots.txt برای همه رباتهای موتورهای جستجو یکسان نیست. این که رباتهای موتورهای جستجو از این دستورات پیروی کنند یا بستگی به دستورالعمل موتور جستجو دارد. یعنی امکان دارد رباتهای گوگل این دستورات را اجرا کنند اما موتور جستوی دیگری مثل یاندکس یا بینگ از این دستورات پیروی نکند.
بهتر است دستورالعملهای هر موتور جستجو را بخوانید تا مطمئن شوید دستوراتی که مینویسید برای همه موتورهای جستجو کار میکند.
۲. امکان دارد هر کدام از رباتها دستورات را به شکل متفاوتی درک کند. یعنی امکان دارد دو ربات متعلق به یک موتور جستجو یا هر سرویسی، یکی از دستورات پیروی کند و دیگری پیروی نکند.
۳. اگر اجازه بررسی صفحهای را با دستورات فایل ربات نداده باشیم باز هم امکان دارد گوگل آن را ایندکس کند و در نتایج جستجو ظاهر شود. ربات گوگل یا باید به صورت مستقیم صفحه را دریافت و بررسی کند (معمولاً به کم نقشه سایت) یا باید از لینکهای دیگری که از صفحهها و سایتهای دیگر به آن صفحه دادهاند آن را پیدا و بررسی کند.
اگر صفحات وبسایت خود را در فایل Robots.txt نوایندکس کنید، گوگل باز هم آن را در نتایج جستجو نمایش میدهد. گوگل به کمک انکرتکست هر لینک و سایر فاکتورها رتبهای به این صفحه در جستجوهای مرتبط میدهد. معمولاً این نوع صفحات در نتایج جستجو بدون توضیحات متا ظاهر میشود چون گوگل محتوای صفحه و توضیحات متا را ذخیره نکرده است.
آشنایی با دستورات فایل Robots.txt و معانیشان
در کل ۴ دستور مهم در فایل Robots.txt نیاز داریم:
- User-agent: برای مشخص کردن رباتی که دستورات برای آن نوشته شده.
- Disallow: بخشهایی که ربات اجازه درخواست یا بررسی آن را ندارد.
- Allow: بخشهایی که مجاز به درخواست و بررسی است.
- Sitemap: برای نشان دادن آدرس فایل نقشه سایت به رباتها.
در ادامه توضیح میدهیم که چطور باید از این دستورها استفاده شود.
۱. مشخص کردن ربات با User-agent
از این دستور برای هدفگیری یک ربات خاص استفاده میشود. از این دستور میتوان به دو شکل در فایل robots.txt استفاده کرد.
اگر میخواهید به تمام رباتهای خزنده یک دستور یکسان بدهید، کافی است بعد از عبارت User-agent از علامت ستاره (*) استفاده کنید. علامت ستاره به معنای «همه چیز» است. مانند مثال زیر:
*:User-agent
دستور بالا به این معنی است که دستورات بعدی، برای همه رباتهای جستجوگر یکسان عمل کند.
اما اگر میخواهید تنها به یک ربات خاص مانند ربات گوگل (GoogleBot) دستور خاصی را بدهید، دستور شما باید به شکل زیر نوشته شود:
User-agent: Googlebot
کد بالا به این معنی است که “اجرای دستورات فایل، تنها برای ربات گوگل الزامی است.
۲. مشخص کردن صفحات و بخشهای غیرمجاز با Disallow
دستور Disallow به رباتها میگوید که چه فولدرهایی از وبسایت شما را نباید بررسی کنند. درواقع این دستور، بیانگر آدرسهایی است که میخواهید از رباتهای جستجو پنهان بماند.
برای مثال اگر نمیخواهید موتورهای جستجو، تصاویر وبسایتتان را ایندکس کنند، میتوانید تمام تصاویر سایت را درون یک پوشه در هاستینگ خود قرار دهید و از دسترس موتورهای جستجو خارج سازید.
فرض کنیم که تمام این تصاویر را به درون فولدری به نام Photos منتقل کردهاید. برای آنکه به گوگل بگویید که این تصاویر را ایندکس نکند، باید دستوری مانند زیر را بنویسید:
* :User-agent
Disallow: /photos
دستور / بعداز Disallow به ربات گوگل میگوید باید وارد پوشهای در ریشه فایل شوی. اسم این پوشه photos است.
این دو خط در فایل robots.txt، به هیچ یک از رباتها اجازه ورود به فولدر تصاویر را نمیدهد. در کد دستوری بالا، قسمت «User-agent: *» میگوید که اجرای این دستور برای تمامی رباتهای جستجو الزامی است. قسمت Disallow: /photos بیانگر این است که ربات، اجازه ورود یا ایندکس پوشه تصاویر سایت را ندارد.
نکته: نیازی نیست آدرس را به صورت کامل جلوی دستور Allow یا Disallow بنویسید.

۳. مشخص کردن بخشهای مجاز برای رباتها با Allow
همانطور که میدانیم ربات خزنده و ایندکس کنندۀ گوگل، Googlebot نام دارد. این ربات نسبت به سایر رباتهای جستجوگر، دستورات بیشتری را متوجه میشود. علاوه بر دستورات “User-agent” و “Disallow”، ربات گوگل دستور دیگری به نام “Allow” را نیز درک میکند.
دستور Allow به شما امکان میدهد تا به ربات گوگل بگویید که اجازه مشاهده یک فایل، در فولدری که Disallowed شده را دارد. برای درک بهتر این دستور، اجازه بدهید که از مثال قبلی استفاده کنیم، بهتر نیست؟
در مثال قبل رشته کدی را نوشتیم که به رباتهای جستجو، اجازه دسترسی به تصاویر سایت را نمیداد. تمام تصاویر سایت را درون یک پوشه به نام Photos قرار دادیم و با دستور زیر یک فایل robots.txt ایجاد کردیم:
* :User-agent
Disallow: /photos
حال تصور کنید درون این پوشهی ما که در هاستینگ سایت قرار دارد، تصویری به نام novin.jpg وجود دارد که میخواهیم Googlebot آن را ایندکس کند. با استفاده از دستور Allow میتوانیم به ربات گوگل بگوییم که این کار را انجام دهد:
* :User-agent
Disallow: /photos
Allow: /photos/novin.jpg
این دستور به ربات گوگل میگوید علی رغم اینکه فولدر Photos از دسترس رباتها خارج شده است، اجازه مشاهده و ایندکس فایل novin.jpg را دارد.
۴. نقشه سایت
گوگل برای وبمسترها و صاحبان وبسایتها چند راه برای دسترسی به نقشه سایت گذاشته است. یکی از این راهها نوشتن آدرس فایل در فایل است.
Sitemap: https://example.com/sitemap.xml
هیچ الزامی وجود ندارد که آدرس نقشه سایت را از این راه به رباتهای گوگل نمایش دهید. بهترین راه ارائه نقشه سایت به گوگل استفاده از ابزار سرچ کنسول است.
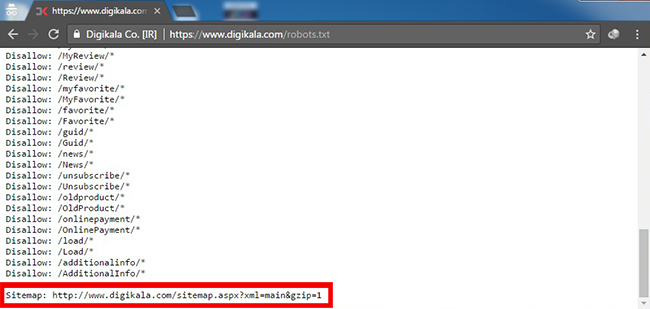
همانطور که میبینید دیجیکالا دستور سایت مپ را در فایل robots.txt خود قرار داده است.
در بخش بعد توضیح میدهیم که چطور یک فایل Robots.txt بسازیم، آن را در جای درستش قرار دهیم و تست کنیم تا رباتهای گوگل به آن دسترسی داشته باشند.
فایل Robots.txt کجاست؟
اگر ترغیب شدید که نگاهی به فایل robots.txt سایت خودتان یا هر سایتی بیاندازید، پیدا کردنش سخت نیست.
تمام کاری که باید انجام دهید این است که یک آدرس معمولی در مرورگر خود وارد کنید (برای مثال novin.com یا هر سایت دیگری). سپس، عبارت robots.txt/ را در انتهای URL وارد کنید.
با انجام این کار فایل robots را در مرورگر میبینید. درست مثل تصویر زیر.
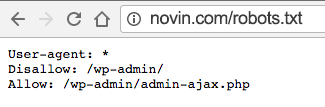
با نگاه کردن به فایلهای robots.txt دیگر سایتها میتوانید از آنها برای سایت خودتان الگو بگیرید.
فایل Robots.txt در قسمت Root سایت شما قرار دارد. برای دسترسی به دایرکتوری Root وبسایتتان میتوانید به اکانت هاستینگ وبسایت وارد شوید. پس از ورود به قسمت مدیریت فایل بروید.
به احتمال زیاد با چنین صفحهای روبرو خواهید شد.
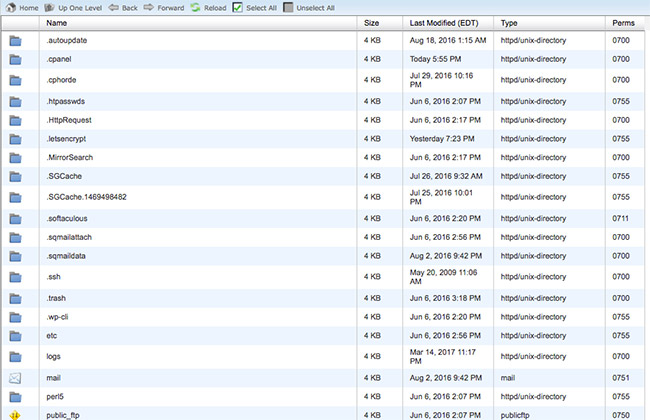
فایل robots.txt خود را پیدا کرده و آن را برای ویرایش باز کنید. دستور جدیدی که میخواهید را وارد کنید و بعد آن را ذخیره کنید.
نکته:این امکان وجود دارد که فایل اصلی را درون دایرکتوری Root وبسایت پیدا نکنید. دلیل این اتفاق این است که بعضی سیستمهای مدیریت محتوا به صورت خودکار یک فایل robots.txt مجازی ایجاد میکند. اگر با چنین مشکلی روبرو هستید، بهتر است که یک فایل جدید برای وبسایتتان ایجاد کنید تا همیشه به آن دسترسی داشته باشید.
ساخت فایل ربات
برای ساخت فایل ربات نیاز به هیچ برنامه خاصی نیست. همان Notepad ساده ویندوز یا هر ویرایشگر متن دیگر که فایل خروجی از نوع TXT میدهد قابل استفاده است.
برای ساخت فایل robots.txt فقط یک فایل txt جدید ایجاد کنید. فرمت یا انکودینگ فایل حتماً باید UTF-8 باشد.
حالا این فایل را باز کنید و طبق راهنمایی که گفته شد، دستورات لازم را در آن بنویسید.
تصویر زیر یک نمونه از فایل ربات ساده است.
بعد از این که فایل را ساختید آن را باید در سرور میزبان سایت آپلود کنید.
بارگذاری فایل Robots در سایت
فایل رباتها باید در ریشه (root) قرار بگیرد. یعنی درست در پوشه اصلی میزبان سایت. این فایل نباید داخل پوشه یا دایرکتوری قرار بگیرد. طوری که آدرس دسترسی به آن مانند مثال زیر باشد:
https://www.example.com/robots.txt
هر حالت دیگری که فایل ربات در ریشه سایت نباشد آن را از دسترس رباتهای گوگل خارج میکند. مثل آدرس زیر که فایل robots در پوشه pages قرار گرفته است.
https://example.com/pages/robots.txt
فرقی نمیکند میزبان وبسایت شما یک سرور اختصاصی، اشتراکی یا مجازی است، فقط کافی است این فایل را در پوشه یا همان دایرکتوری اصلی سایت بارگذاری کنید.
شما میتوانید فایل Robots هر وبسایتی را به راحتی ببینید. کافی است به انتهای آدرس هر سایتی robots.txt/ اضافه کنید و آن را باز کنید.
تست فایل Robots با ابزار گوگل
برای تست این که یک صفحه یا هر نوع فایلی توسط فایل Robots.txt بلاک شده، و همچنین اطمینان از این که خود فایل Robots در دسترس است،میتوانید از ابزار تست کننده در سرچ کنسول گوگل استفاده کنید.
اگر وبسایت خود را به ابزار سرچ کنسول گوگل متصل کرده باشید، وقتی این ابزار تست را باز کنید از شما میخواهد که سایت متصل شده مورد نظر را انتخاب کنید.
بعد از انتخاب وبسایت به صفحهای هدایت میشوید که آخرین محتوای فایل Robots.txt که گوگل دریافت و بررسی کرده را نمایش میدهد. میتوانید فایل را در همین صفحه ویرایش کنید و بعد با زدن دکمه submit صفحهای باز میشود.
در این صفحه مثل تصویر زیر سه دکمه میبینید.
با دکمه اول فایل Robots.txt جدید را دانلود میکنید.
حالا باید این فایل را در سرور میزبان به جای فایل قبلی قرار دهید.
بعد از آپلود، اگر دکمه View uploaded version را بزنید نسخه جدید را باز میکند.
در انتها هم با زدن دکمه submit از گوگل بخواهید تا فایل جدید را دریافت و بررسی کند. اگر این کارها را با موفقیت انجام دهید، ساعت و تاریخ آخرین بررسی فایل ربات به زمانی بعد از درخواست تغییر میکند. برای اطمینان هم میتوانید دوباره از همین ابزار برای مطمئن شدن استفاده کنید.
این ابزار نمیتواند به صورت مستقیم فایل robots.txt را ویرایش کند. بعد از زدن دکمه submit پنجرهای باز میشود که از شما میخواهد فایل جدید ویرایش شده را دانلود کرده و به جای فایل قبلی در سرور میزبان وبسایت جایگزین کنید.
اگر هم میخواهید صفحههای مشخصی را تست کنید، کافی است آدرس آن را در نوار پایینی وارد کنید و بعد ربات گوگلی که مد نظرتان است را انتخاب کنید. هر بار که دکمه test را بزنید در همان لحظه به شما نشان میدهد اجازه دسترسی رباتها به صفحه را دادهاید یا نه.
مثلاً میتوانید بررسی کنید آیا ربات مخصوص تصاویر گوگل به یک صفحه خاص دسترسی دارد یا نه. امکان به همان صفحه اجازه دسترسی ربات وب را داده باشید اما ربات تصاویر مجاز به دریافت تصاویر و نمایش آن در نتایج جستجو نباشد.
میتوانید سرعت crawl rate رباتها را به جای محدود کردن کم کنید
https://www.google.com/webmasters/tools/settings
کجاست
بهینه سازی
چه صفحاتی باید مخفی شوند؟
خبر گوگل برای استفاده نکردن از ربات برای نوایندکس کردن
چطور از گوگل بخواهیم صفحهای را در نتایج جستجو نمایش ندهد؟
گوگل بعد از این که گفت استفاده از دستورات noindex و disallow کمکی به خارج کردن صفحات از نتایج جستجو نمیکند، راهکارهای دیگری برای این کار معرفی کرد.
گوگل میگوید اگر میخواهید صفحههایی از نتایج جستجو به صورت کامل حذف شوند باید دستوران noindex را در همان صفحه قرار دهید.
راحتترین راه حذف کردن صفحهای از نتایج جستجو استفاده از دستورهای به اصطلاح متا تگ (meta tag) در قسمت هد (head) صفحه است.
برای افزودن این کدها یا باید مستقیم کدهای HTML صفحه را ویرایش کنید یا این که از راهای دیگری مثل افزونهها برای نوایندکس کردن استفاده کنید. در واقع افزونهها هم فقط این کد را به صفحه اضافه میکنند.
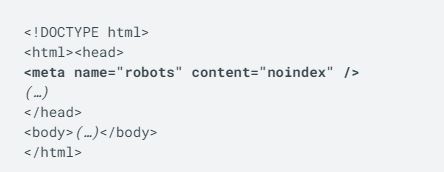
اگر کمی با کدهای HTML آشنایی داشته باشید پس میدانید که هر صفحه دو قسمت هد (head) و بدنه (body) دارد. دستور نوایندکس را باید در قسمت هد قرار دهید.
بنابراین، کد شما باید این شکلی شود:
خب این هم فایل رباتها!
تقریباً دیگر حرفی برای گفتن باقی نمانده! هر آنچه برای کنترل این رباتها فضول اما مفید لازم بود را به زبان ساده توضیح دادیم.
این فایل را فقط یکبار باید آماده کنید و دیگر کاری با آن نخواهید داشت مگر این که تغییرات مهمی در ساختار سایت ایجاد کنید.
امیدوراریم این آموزش هم برای شما مفید بوده باشد. مثل همیشه منتظر نظرات مثبت و سوالات احتمالی شما هستیم.
نوشته فایل Robots.txt چیست و چه کاربردی دارد؟ اولین بار در نوین. پدیدار شد.